
Unicode与字符编码
字符集与字符编码
基础知识
字符编码的几个概念
计算机中储存的信息都是用二进制数表示的;而我们在屏幕上看到的英文、汉字等字符是二进制数转换之后的结果。
维基百科中的 “字符编码” 词条提到下列概念:
-
字符集(Character Set)
是一个系统支持的所有抽象字符的集合。字符表可以是封闭的,不允许添加新的符号;字符表也可以是开放的,即允许添加新的符号(Unicode和一定程度上代码页是这方面的例子)。
如:ASCII字符集中包含的128个字符,GB2312-80字符集中收录了6763个字符。
-
编码字符集(CCS:Coded Character Set)
就是对字符集中每个字符指定一个数字编码。其中的每个数字叫做码点。
例如,在一个给定的字符表中,表示大写拉丁字母“A”的字符被赋予整数65、 字符“B”是66,如此继续下去。多个编码字符集可以表示同样的字符表,例如 ISO-8859-1和IBM的代码页037和500含盖同样的字符集但是将它们映射为不同的代码。
UNICODE、UCS-4、UCS-2、GB2312、GB18030都是编码字符集。
-
字符编码表(CEF:Character Encoding Form)
就是怎么把编码字符集中的整数代码转换成若干固定位数的编码单位(8bit 、16bit、32bit等)。
-
最简单的字符编码表就是单纯地选择足够大的单位,以保证编码字符集中的所有数值能够直接编码(一个码点对应一个码值)。如传统非CJK编码(8位),或早期版本的Unicode(16位)。这种情况下,字符编码表就等于编码字符集。
-
随着编码字符集的大小增加,很多系统都使用变长的编码,如UTF-8、UTF-16。
UTF-8、UTF-16、UTF-32都对应到相同的编码字符集,但使用的固定位数分别为8位、16位、32位。
GB2312、GBK、GB18030等使用的固定位数都为8位。
-
-
字符编码方案(CES:Character Encoding Scheme)
定义如何将整数代码对应到适合基于8位字节数据的文件系统存储或用于网络传输。
多数使用Unicode的场合,使用BOM(Byte Order Mark)来指定字节顺序是大端序或者小端序。
UTF-16LE、UTF-16BE。
代码页(Code page)
-
代码页是字符编码方案的别名,也有人称”内码表”。
-
早期的操作系统直接使用BIOS供应的VGA功能来显示字符,只能支持一套字符编码。IBM为每套字符编码指定了一个16位的数字编码。
-
目前代码页用得已经不多了,但很多微软程序还使用这些数字来指定编码。
-
常见代码页
- CP437:原始的 IBM PC 代码页
- CP936:简体中文,微软的CP936通常被视为等同GBK
- CP950:繁体中文(大五码)
字节序(Endian)

“endian”一词来源于乔纳森·斯威夫特的小说格列佛游记。小说中,小人国为水煮蛋该从大的一端(Big-End)剥开还是小的一端(Little-End)剥开而争论,争论的双方分别被称为Big-endians和Little-endians。
-
大端序(big-endian)
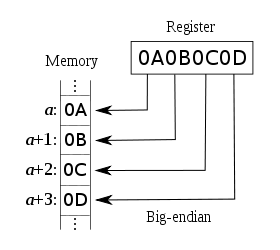
最高有效位(MSB, Most Significant Byte)是0x0A 存储在最低的内存地址处。下一个字节0x0B存在后面的地址处。正类似于十六进制字节从左到右的阅读顺序。
-
小端序(little-endian)
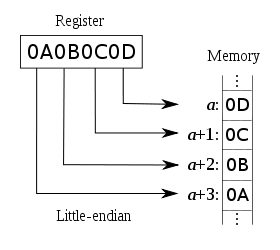
最低有效位(LSB,Least Significant Byte)是0x0D 存储在最低的内存地址处。后面字节依次存在后面的地址处。
-
不同处理器体系支持不同的字节序:
- x86,MOS Technology 6502,Z80,VAX,PDP-11等处理器为Little endian。
- Motorola 6800,Motorola 68000,PowerPC 970,System/370,SPARC(除V9外)等处理器为Big endian
- ARM, PowerPC (除PowerPC 970外), DEC Alpha, SPARC V9, MIPS, PA-RISC, IA64的字节序是可配置的。
-
网络传输一般采用大端序,也被称之为网络字节序,或网络序。IP协议中定义大端序为网络字节序。
NOTE: 伯克利socket API定义了一组转换函数,用于16和32bit整数在网络序和本机字节序之间的转换。
htonl,htons用于本机序转换到网络序;ntohl,ntohs用于网络序转换到本机序。
几种常见字符编码
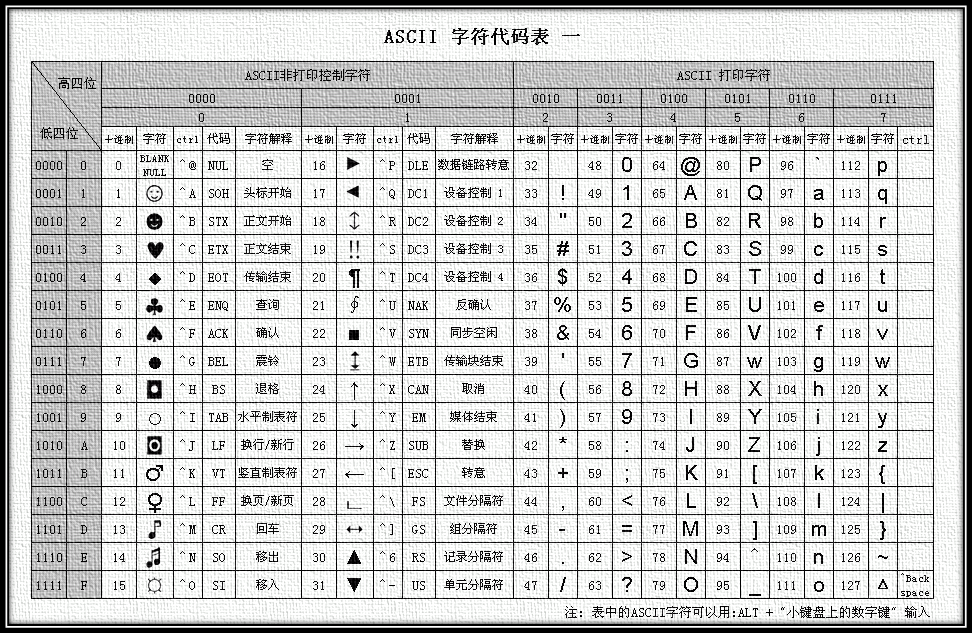
ASCII
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语。
-
ASCII字符集
主要包括控制字符(回车键、退格、换行键等);可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
-
ASCII编码
将ASCII字符集转换为计算机可以接受的数字系统的数的规则。使用7位(bits)表示一个字符,共128字符;但是7位编码的字符集只能支持128个字符,为了表示更多的欧洲常用字符对ASCII进行了扩展,ASCII扩展字符集使用8位(bits)表示一个字符,共256字符。
GBXXXX系列
GB2312
GB 2312 或 GB 2312-80 是中国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,又称GB0,由中国国家标准总局发布,1981年5月1日实施。
GB2312共收录6763个汉字,覆盖中国大陆99.75%的使用频率
GB2312规定:
- 一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字;
- 前面的一个字节(称之为高字节)从0xA1用到 0xF7,后面一个字节(低字节)从0xA1到0xFE,这样就可以组合出大约7000多个简体汉字。
- 数学符号、罗马希腊的 字母、日文的假名们都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的”全角”字符,而原来在127号以下的那些就叫”半角”字符。

GBK
GBK即汉字内码扩展规范。
1993年,Unicode 1.1版本推出,收录中国大陆、台湾、日本及韩国通用字符集的汉字,总共有20,902个。中国大陆订定了等同于Unicode 1.1版本的“GB 13000.1-93”“信息技术通用多八位编码字符集(UCS)第一部分:体系结构与基本多文种平面”。
由于GB 2312-80只收录6763个汉字,有不少汉字并未有收录在内,于是厂商微软利用GB 2312-80未使用的编码空间,收录GB 13000.1-93全部字符制定了GBK编码。
最早实现于Windows 95简体中文版。虽然GBK收录GB 13000.1-93的全部字符,但编码方式并不相同。
-
GBK自身并非国家标准,只是曾由国家技术监督局标准化司、电子工业部科技与质量监督司公布为“技术规范指导性文件”。原始GB13000一直未被业界采用,后续国家标准GB18030技术上兼容GBK而非GB13000。
-
GBK的第二字节使用了0x40至0x7E的范围,由于这个范围内包含一些特殊字符(如“ ”、“\”),因此可能会被一些程序误处理。由于保持与GBK的兼容性,GB18030也有同样的问题。
GB18030
GB 18030,最新版本为GB 18030-2005,其全称为中华人民共和国国家标准GB 18030-2005《信息技术 中文编码字符集》,与GB 2312-1980完全兼容,与GBK基本兼容,支持GB 13000及Unicode的全部统一汉字,共收录汉字70244个。
GB18030有以下特点:
- 与 UTF-8 相同,采用多字节编码,每个字可以由1个、2个或4个字节组成。
- 单字节部分使用0x00至0x7F码位。
- 双字节部分采用两个字节表示一个字符,其首字节码位从0x81至0xFE,尾字节码位分别是0x40至0x7E和0x80至0xFE。
- 四字节部分,第一个字节的编码为0x81至0xFE;第二个字节的编码范围为0x30至0x39;第三个字节编码范围为0x81至0xFE;第四个字节编码范围为0x30至0x39。
- 编码空间庞大,最多可定义161万个字符。(能表示所有Unicode码点,其映射关系一部分要通过查表得出,一部分可以通过算法求出)
- 支持中国国内少数民族的文字,不需要动用造字区。
- 汉字收录范围包含繁体汉字以及日韩汉字
Unicode
Unicode的由来
Unicode(统一码、万国码、单一码、标准万国码)是计算机科学领域里的一项业界标准,用以统一地呈现和处理世界上大部分的文字系统,并为其编码。
传统字符编码方案的主要缺陷:
- 由于不同的系统采用不同的字符编码,导致多个系统间难以进行数据交换。
- 由于不同字符编码方案可能使用相同的编码区间,同一个数值在不同编码方案中有不同的含义,因此电脑系统难以同时支持多语种。
为解决传统字符编码的问题,制定了一个国际标准,叫做Unicode。Unicode为每个字符提供了唯一的特定数值,不论在什么平台上、不论在什么软件中,也不论什么语言。也就是说,它世界上使用的所有字符都列出来,并给每一个字符一个唯一特定数值。
Unicode一般使用U+hhhh的方式表示。如U+6731就是“朱”字。
UCS与Unicode
-
通用字符集(Universal Character Set,UCS)是由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的标准字符集。
-
Unicode则是由统一码联盟(英语:The Unicode Consortium)(主要由来自多个国家政府和各大软件商的代表参与)制定。
-
ISO 10646和Unicode最初是不同的标准:
-
ISO10646定义了128组(groups)256平面( planes)256行(rows)*256字位 (cells)=2^31^个码点,实际上排除了一些不可用的控制字符后,可用 79,477,248个码点。
-
Unicode只使用16位,65536个码点。
-
-
业界认为ISO 10646太复杂,占用太多空间(4字节),因而不愿意接受。标准 制订者也认识到这点,因此将基本字符平面(U+0000至U+FFFF)保持与Unicode(16 bit)一致。
-
随着应用的发展,Unicode的16 bit也不够用,因此Unicode从v2.0开始扩展为包含17个平面,1,112,064个码点。对应UCS U+00000000 ~ U+00100000区间。
-
ISO 10646和Unicode两个项目独立地公布各自的标准,但双方都同意保持两者标准的码表兼容,并紧密地共同调整任何未来的扩展。在使用时,基本可以把UCS和Unicode视为相同的概念。
| 平面 | 始末字符值 | 中文名称 | 英文名称 |
|---|---|---|---|
| 0号平面 | U+0000 - U+FFFF | 基本多文种平面 | Basic Multilingual Plane,简称BMP |
| 1号平面 | U+10000 - U+1FFFF | 多文种补充平面 | Supplementary Multilingual Plane,简称SMP |
| 2号平面 | U+20000 - U+2FFFF | 表意文字补充平面 | Supplementary Ideographic Plane,简称SIP |
| 3号平面 | U+30000 - U+3FFFF | 表意文字第三平面 | Tertiary Ideographic Plane,简称TIP |
| 4号至13号平面 | U+40000 - U+DFFFF | (尚未使用) | |
| 14号平面 | U+E0000 - U+EFFFF | 特别用途补充平面 | Supplementary Special-purpose Plane,简称SSP |
| 15号平面 | U+F0000 - U+FFFFF | 保留作为私人使用区(A区) | Private Use Area-A,简称PUA-A |
| 16号平面 | U+100000 - U+10FFFF | 保留作为私人使用区(B区) | Private Use Area-B,简称PUA-B |
UCS-2与UCS-4
-
ISO 10646定义了三种字符编码方式:
-
UCS-4,每个字符使用4个字节,可以编码所有UCS字符。
-
UCS-2,每个字符使用2个字节,只可以编码0号平面的字符。编码从 U+0000至U+FFFF。
Unicode的早期版本也只支持2个字节,与UCS-2一致。
-
UTF-1,每个字符使用1~5字节的变长编码。基本上被UTF-8取代。
-
UTF
Unicode只是一种编码字符集(CCS:Coded Character Set),定义字符与编码之间的关系。但在实际应用中,还需要定义怎样传输Unicode编码,这就是Unicode 转换格式(Unicode Transformation Format,简称为UTF)。
目前常用的Unicode实现方式:
-
UTF-8:变长编码,每个字符使用一到六个字节。基本7位ASCII字符仍用7位编码表示,占用一个字节(首位补0),汉字等大部分常用字使用3个字节(首字节为Ex)。
虽然UTF-8最长可以支持6个字节,但2003年11月UTF-8被RFC 3629重新规范,只能使用原来Unicode定义的区域,U+0000到U+10FFFF,最长4个字节,最大的字符是
F4 8F BF BF。Unicode码点 UTF-8编码 U-00000000 – U-0000007F 0xxxxxxx U-00000080 – U-000007FF 110xxxxx 10xxxxxx U-00000800 – U-0000FFFF 1110xxxx 10xxxxxx 10xxxxxx U-00010000 – U-001FFFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx U-00200000 – U-03FFFFFF 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx U-04000000 – U-7FFFFFFF 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx -
UTF-16:变长编码,对于BMP平面内的字符使用两个字节,对于其它平面的字符使用四个字节。根据字节顺序,又可以分为UTF-16 LE和UTF-16 BE。Windows和Linux中,默认为UTF-16 LE。
- UTF-16是UCS-2的超集。
- UCS-2只能使用2字节编码。
- UTF-16是2字节或4字节的变长编码。其2字节部分兼容UCS-2。
- 通常如果一个软件声称能支持UCS-2,往往暗示其不能支持UTF-16 中超过2字节的部分。
- UTF-16是UCS-2的超集。
NOTE: 在Windows记事本程序中,“另存为”对话框可以选择四种编码,ANSI为非Unicode编码(对应于当前系统内码,如GBK),其余三种为“Unicode”(对应UTF-16 LE)、“Unicode big endian”(对应UTF-16 BE)和“UTF-8”
UTF-8 vs UCS-2
UTF-8
-
优点
- 完美兼容ASCII(0x00到0x7F)。
- Linux的内核是UTF-8的,意味着在Linux下使用UTF-8有得天独厚的优势。而且不仅仅是Linux,大量的开源计划(由于大部分开源计划都是围绕着Linux走的),包括网页,XML等也都是原生UTF-8的,可参考源程序范例更多。
- 单字节编码,从一个字节到四个字节,不用考虑大头小头的字节序问题。
- 自同步,可以轻易识别字符的开始及字符占用的字节数。
-
缺点
- 大量的组合字符(即用两个以上字节来表示一个字符),使得字符串的处理很不方便。
- 以非ASCII字符为主的数据在存储时,占用空间较大。
UCS-2
- 优点
- 统一定长编码,两个字节对应一个字符,对于字符串的处理非常方便。大量的宽字节C/C++函数都可以直接使用。
- Windows的内核是UTF-16的,由于UCS-2是UTF-16的一个子集,所以在Windows下使用UCS-2,有得天独厚的优势。另外,从资料上看,使用UTF-16/UCS-2的操作系统阵营比使用UTF-8的更加庞大。
- 缺点
- UCS-2只能表示Unicode的一个子集,有部分字符不在UCS-2表示范围内。
- 在 Unix 下使用 UCS-2 (或 UCS-4) 会导致非常严重的问题。用这些编码的字符串会包含一些特殊的字符,比如’\0’或’/’,它们在文件名和其他 C 库函数参数里都有特别的含义. 另外, 大多数使用 ASCII 文件的 UNIX 下的工具, 如果不进行重大修改是无法读取 16 位的字符的. 基于这些原因, 在文件名, 文本文件, 环境变量等地方, UCS-2 不适合作为 Unicode 的外部编码。
Wide character/宽字符
宽字符(Wide character)是程序设计的术语。它是一个含糊的术语,用以表示比8位字符还宽的数据类型。
C/C++中,以wchar_t类型表示宽字符。
宽字符 vs MBCS/多字节字符集
C标准中,
-
MBCS指的是使用固定或可变数量的字节来表示单个字符。一个字符占用多个逻辑单元。
-
宽字符指的是在程序运行过程中通过一个对象来表达一个字符。一个字符占用一个逻辑单元。
(Wide characters) which are run-time representations of characters in single objects
宽字符 vs Unicode
-
宽字符只表示不小于8位的字符(在C/C++标准中,只要求wchar_t的大小不小于8位),并没有规定使用何种字符编码。
-
在很多程序设计语言中,宽字符中存放的是Unicode数值。
-
由于受以前使用UCS-2的影响,Win 32/Win 64 API以及Java/.Net Framework都把宽字符的大小定义为16位,采用UTF-16编码。
-
类Unix系统一般把宽字符的大小定义为32位,采用UTF-32编码。
常用操作、配置
Unicode字符的录入
- 很多输入法都支持Unicode字符
- 通常可以通过字符映射表之类的程序,直接从屏幕上选择所需的字符
- Windows下在开始-运行中,输入charmap即可打开“字符映射表”程序
- Mac OS X/GNOME/KDE都有相应的工具程序
- Windows的RTF控件(包括在写字版程序及Word中),有两种输入Unicode字符的方式:
- 输入字符对应的4位16进制Unicode编码,再按
Alt-X - 按住
Alt键不放,在小键盘上输入字符对应的10进制编码,放开Alt键
- 输入字符对应的4位16进制Unicode编码,再按
- 在Vim中,先输入Ctrl-V,然后按字母u,再输入4位16进制Unicode字符编码
- 在GTK+程序,如GNOME中,可以先按
Ctrl-Shift-u,放开,再输入4位16进制Unicode编码,再按Enter键
LC_ALL、LC_*、LANG等不同变量的含义
-
POSIX系统中有12个LC_变量,分别设置语言环境的不同方面,还可以设置 LC_ALL,该设置将覆盖这12项LC_设置。
-
变量优先级的关系:LC_ALL > LC_* >LANG
-
变量含义
编码 含义 zh_CN.UTF-8 简体中文,使用UTF-8编码 zh_CN.GB18030 简体中文,使用GB18030编码 en_US.UTF-8 美国英语,使用UTF-8编码 en_US.GB18030 美国英语,使用GB18030编码 - 语言代码_国家代码.编码
- 语言代码和国家代码决定软件界面使用什么语言(如
ls --help时,显示中文帮助还是英文帮助信息) - 编码决定各种字符使用何种字符编码来表示
12个LC_*变量的具体含义如下:
| LC_CTYPE | 语言符号及其分类。决定系统的内码。 |
| LC_NUMERIC | 数字 |
| LC_COLLATE | 比较和排序习惯 |
| LC_TIME | 时间显示格式 |
| LC_MONETARY | 货币单位 |
| LC_MESSAGES | 信息。主要是提示信息,错误信息,状态信息,标题,标签,按钮和菜单等 |
| LC_NAME | 姓名书写方式 |
| LC_ADDRESS | 地址书写方式 |
| LC_TELEPHONE | 电话号码书写方式 |
| LC_MEASUREMENT | 度量衡表达方式 |
| LC_PAPER | 默认纸张尺寸大小 |
| LC_IDENTIFICATION | 对locale自身包含信息的概述 |
设置区域环境的方法
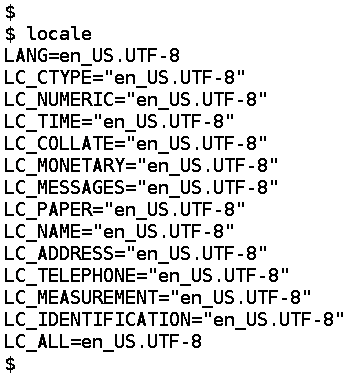
Linux
-
通过
locale命令可以查看上述LC_*,LANG等变量的状态 - 设置整个环境为简体中文UTF-8环境:
export LC_ALL=zh_CN.UTF-8 - 把内码设置UTF-8,其它环境保持不变:
export LC_CTYPE=zh_CN.UTF-8
Windows
- 可以通过“控制面板”——“区域和语言”——“管理”——“更改系统区域设置”进行修改
putty乱码问题的解决
![]()
- putty配置中,Window-Translation-Remote character set的设置要与服务器的设置一致。
vim的字符编码
set fileencodings=utf-8,ucs-bom,gb18030,gbk,gb2312,cp936
MySQL的UTF-8编码
MySQL中,由于历史原因,utf8是utf8mb3的别名,只支持BMP平面,3字节的UTF-8字符。后来版本的MySQL中,引入了utf8mb4,支持完整的Unicode字符集。
MySQL文档(MySQL: MySQL 8.0 Reference Manual :: 10.9.3 The utf8 Character Set (Alias for utf8mb3))中明确提出应该使用utf8mb4而不是utf8/utf8mb3,并指出以后utf8会被改为utf8mb4的别名:
The utf8mb3 character set is deprecated and you should expect it to be removed in a future MySQL release. Please use utf8mb4 instead. Although utf8 is currently an alias for utf8mb3, at some point utf8 is expected to become a reference to utf8mb4. To avoid ambiguity about the meaning of utf8, consider specifying utf8mb4 explicitly for character set references instead of utf8.
相关内容
几个单词
-
*i18n: Internationalization,国际化。指在设计软件,将软件与特定语言及地区脱钩的过程。当软件被移植到不同的语言及地区时,软件本身不用做内部工程上的改变或修正。
-
L10n: Localization,本地化。指当移植软件时,加上与特定区域设置有关的信息和翻译文件的过程。使用大写的L以利区分i18n中的i。
-
g11n: Globalization,全球化。微软及IBM等企业中,会使用全球化一词来作为国际化和本地化两者的合称
HTTP头中,与字符编码有关的部分
在HTTP中,与字符集和字符编码相关的消息头是Accept-Charset/Content-Type,另外还有一些容易混淆的消息头:
-
Accept-Charset:浏览器申明自己接收的字符集,这就是本文前面介绍的各种字符集和字符编码,如gb2312,utf-8(通常我们说Charset包括了相应的字符编码方案);
-
Accept-Encoding:浏览器申明自己接收的编码方法,通常指定压缩方法,是否支持压缩,支持什么压缩方法(gzip,deflate),(注意:这不是只字符编码);
-
Accept-Language:浏览器申明自己接收的语言。语言跟字符集的区别:中文是语言,中文有多种字符集,比如big5,gb2312,gbk等等;
-
Content-Type:WEB服务器告诉浏览器自己响应的对象的类型和字符集。例如:Content-Type: text/html; charset=’gb2312’
-
Content-Encoding:WEB服务器表明自己使用了什么压缩方法(gzip,deflate)压缩响应中的对象。例如:Content-Encoding:gzip
-
Content-Language:WEB服务器告诉浏览器自己响应的对象的语言。
参考资料
- 字符编码: http://zh.wikipedia.org/wiki/%E5%AD%97%E7%AC%A6%E7%BC%96%E7%A0%81
- Unicode: http://zh.wikipedia.org/wiki/Unicode
- Universal Character Set: http://en.wikipedia.org/wiki/Universal_Character_Set
- UTF-8: https://zh.wikipedia.org/wiki/UTF-8
- UTF-16: http://zh.wikipedia.org/wiki/UCS-2
- Unicode字符平面映射: http://zh.wikipedia.org/wiki/Unicode%E5%AD%97%E7%AC%A6%E5%B9%B3%E9%9D%A2%E6%98%A0%E5%B0%84
- GBK: http://zh.wikipedia.org/wiki/GBK
- 代码页: http://zh.wikipedia.org/wiki/%E4%BB%A3%E7%A0%81%E9%A1%B5
- Wide character: http://en.wikipedia.org/wiki/Wide_character
- 区域设置: http://zh.wikipedia.org/wiki/%E5%8C%BA%E5%9F%9F%E8%AE%BE%E7%BD%AE
- 字符集和字符编码(Charset & Encoding): http://www.cnblogs.com/skynet/archive/2011/05/03/2035105.html
- UTF-8 and Unicode FAQ: http://www.linuxforum.net/books/UTF-8-Unicode.html
- C++的中英文字符串表示(string,wstring): http://www.cnblogs.com/xiaoyz/archive/2008/10/11/1308860.html
- 彻底解密C++宽字符: http://www.cppblog.com/lf426/archive/2010/06/25/118707.html
- UCS-2与UTF8之间的选择: http://blog.csdn.net/vagrxie/archive/2009/03/01/3947195.aspx
Comments